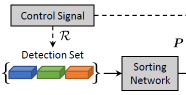
LAMV is being used at Facebook to detect harmful content
A solution for matching and detecting copied videos, developed by AImageLab and Facebook AI Research, is now being used in production scale at Facebook to detect harmful content.
August 03, 2019
Read more ↗
Press